
I had a great time speaking at ODSC East this week. I am grateful for a fantastic and engaged audience. It was wonderful to hear that many found my talk helpful. Hopefully it can be of even more help here–
Category: Uncategorized
Quick Little Hack: Camera-Ready Scripts and LaTex From Jupyter Notebooks
I’m rounding that corner of my research where the end seems to be in sight–which also means that properly formatting my work for publication can’t be put off too much longer. Depending what I’m coding, I’m either in PyCharm, Sublime, or Jupyter. My dissertation is, of course, in LaTex(…as well on my whiteboard, scattered printer paper, post its, long forgotten notebooks, and the margins of so many journal papers). If my work is already in a script, then getting it to LaTex is a snap. But if it’s written in Jupyter, it needs a little love before it’s fit for prime-time.

From Script to Latex
There’s a nice little package for LaTex that imports your python script (your_script.py) and presents it neatly
\usepackage{listings}
and you can include your script via
\lstinputlisting[language=Python]{path/to/your_script.py}
It will appear nicely formatted with appropriate bolding, etc.
That’s great if your scripts already looks nice. And sure, some of mine do. But I’ve built a few simulations in Jupyter notebook.
From Jupyter Notebook to Script
There is a convenient means to create a python executable from your notebook. You can run this in your terminal
jupyter nbconvert --to script path/to/your_notebook.ipynb
This will produce a your_notebook.py executable. It’s fine if you just want to run it, but it’s not all that great to look at. It includes cell numbers, awkward spacing, and just looks a bit messy. It’s not what I want in my dissertation. And I’m certainly not going to open up each file and tidy them up manually–especially not every time I tweak and edit my code. I know I will eventually forget to export and tidy the updated script. So, let’s just make it mindless.
From Jupyter Notebook to Script-Fit-For-Latex
Using a little magic(!) and a bit of processing, I added these lines to the end of my notebooks. (Don’t worry–I’ve also added the code below for copy-paste purposes.)

NOTE: The first cell is markdown (the rest are python cells):
# DO NOT ADD BELOW TO SCRIPT
The next two cells are magic-ed (the ‘!’ at the beginning). The first converts this_notebook.ipynb (the actual name of the notebook you’re currently in) to this_notebook.py
! jupyter nbconvert --to script this_notebook.ipynb
The next cell is optional, but there’s a good chance you want it for organizational purposes (especially if, as I recommend, you are versioning your work via github/gitlab/etc). Also, if your notebook takes a long time to run, consider copying (cp) instead of moving (mv) your file. This will come up at the end.
! mv this_notebook.py your/desired/location/this_notebook.py
The next cell will rewrite your script in place, but leave out the extraneous stuff. NOTE: you will have to update f_name
import re
f_name = "your/desired/location/this_notebook.py"
do_not_add_below_to_script = "# DO NOT ADD BELOW TO SCRIPT" # must match the markdown above!
skip = 0
cell_nums = re.escape("# In[") + r"[0-9]*" + re.escape("]:")
with open(f_name, "r") as f:
lines = f.readlines() # get a list of lines from the converted script
with open(f_name, "w") as f: # overwrite the original converted script
for line in lines:
if re.search(cell_nums , line.strip()): # don't include the '#In[##]:' lines
skip = 2
elif skip > 0 and line == "\n": # trim extra blank lines below #In[##]:' lines
skip -=1
elif re.search(do_not_add_below_to_script, line): # don't include this code
break
else:
f.write(line)
Make sure to update you LaTex path as well
\lstinputlisting[language=Python]{your/desired/location/this_notebook.py}
If the Script isn’t updating… Don’t Worry!!!
It just means nb convert is looking at a previous version (annoying, I know). In Jupyter Notebook, just go to File –> Save & Checkpoint. Then rerun this code.
If LaTex isn’t updating… Don’t Worry!!!
LaTex if finicky. We all know that. Fortunately, when an imported file isn’t updating the fix is usually the same.
Delete the your/desired/location/this_notebook.py file. Rebuild your LaTex file so that you get an error (or just delete the appropriate build file). Then rerun the code I’ve shown here — but if you chose just to copy your file, run only that cell and below.
Hope this helps! I look forward to seeing your beautiful code in a publication somewhere soon!
Oldies But Goodies: “On AI ROI: The Questions You Need To Be Asking”
As promised in my previous post, here’s a complimentary talk to that one.
Giving this talk was particularly memorable because I was back in the Bay Area, back where I got my data science-in-business start, and back with so many of my first data colleagues. After learning so much from the data community in NorCal, it was a joy to bring them something in return.
To be honest, I was a bit worried that the audience would find this very practical, very look-behind-the-curtain talk too irreverent to the myth of the all-magical, all-fixing data science. But I was delighted to find the talk very well received. In the midst of the data science hype, a bit of bubble bursting and some guidelines for practical oversight seemed to be just what was needed.
“Chasing Impact” Talk at the GET Cities Kickoff Summit
A few weeks ago (January 23rd, 2021 to be precise) I had the pleasure of joining GET Cities for their inaugural Kickoff Summit! GET Cities is an incredible fellowship program building a more inclusive future for tech by fostering community and accelerating growth in underrepresented genders. If you’re looking for the up-and-coming movers and shakers, look no further than GET Cities.
I was asked to speak about technical project development and building successful products. I very happily obliged. Hope you enjoy the deck!
Why & When: Cross Validation in Practice
Nearly every time I lead a machine learning course, it becomes clear that there is a fundamental acceptance that cross validation should be done…and almost no understanding as to why it should be done—or how it is actually done in a real-world workflow. Finally I’ve decided to move my answers from the white board to the blog post. Hope this helps!
Cross validation is like standing in a line in San Francisco: Everyone’s doing it, so everybody does it, and if you ask someone about it, chances are they don’t know why they’re doing it.
Fortunately for those who might be doing so without fully knowing why, there is very good reason to cross validate (which is generally not true about joining any random Bay Area queue).
So, other than our now inbred inclination as data scientists to do the thing that everyone else is doing…why should we cross validate?
The Why & the When
To discuss why we perform cross-validation, it’s easiest to review how and when we incorporate cross validation into a data science workflow.
To set the stage, let’s pretend we’re not doing a GridSearchCV. Just good old fashioned cross validation.
And, let’s forget about time. Time of observation usually matters quite a bit…and that complicates things…quite a bit. For right now let’s pretend time of observation doesn’t matter.
First Partition of Data
Divide your data into a holdout set (maybe you prefer to call it a testing set?) and the rest of your data.
What’s a good practice here? If you’re data isn’t too big, import your entire_dataset, randomly sample [your chosen holdout percent]% of observation ids (or row indices). Create two new data frames, holdout_data and rest_of_data. Clear your variable entire_dataset. Export holdout_data to the file or storage type of your convenience, and clear your variable holdout_data.
If your data is too big, adapt a similar workflow by using indices instead of data frames and only loading data when necessary.
To clear a variable in python, you’re welcome to del your variable or set it to Null, as you’d like. Just make sure you can’t access the data by accident.
EDA & Feature Engineering
Let’s assume we then follow good practices around exploratory data analysis and creating a reusable feature engineering pipeline.
Notice that we’re only using the rest_of_data for EDA and designing our feature engineering pipeline. Let’s think about this for a second. Only doing this on the rest_of_data allows us to test the entire modeling process when we test on the holdout data. Clever, right?
Now, we’ve got our data ready to go and we have an automated way to process new data, via our pipeline.
Specify a Model
We need to specify a model, e.g. choose to use ‘random forest’. For this non-grid-search scenario, we’re going to also say this is where tuning occurs.
Cross Validation
Now we cross-validate.
You know the idea: take the rest_of_data, partition it into k folds (partition). For step j[j]_train_set (all the data but the jth partition) and a [j]_test_set (the jth partition). Train on the training set, test on the test set, record the test performance, and throw away the trained model. Do this for all k partitions.
Or, more likely, have sklearn do it for you.
Go ahead, we’ll wait.
Now we have k data points of “sample performance” of our specified model.
We inspect these results by looking at the mean (or median) score and the variance. This is the key to why we cross validate.
Why We Perform Cross Validation:
We want to get an idea of how well the specified model can generalize to unseen data and how reliable that performance is. The mean (or median) will gives us something like expected performance. The variance gives us an idea of how likely it is to actually perform near that ‘expected’ performance.
I’m not making this up–you can look at the sklearn docs and they, too, look at the variance. Some people even plot out the performances.
If you’re coming from a traditional analytics or statistics background, you might think “don’t we have theories for that? don’t we have p-values for that? don’t we have modeling assumptions for that?” The answer is, generally, no. We don’t have the same strong assumptions around the distribution of data or the performance of models in broader machine learning as we do in, say, linear models or GLMs. As a result, we need to engineer what we can’t theory [sic]. Cross validation is the engineered answer to “how well will this perform?”
Assuming the performance measures are acceptable, we’ve now found a specification of a model we like. Huzzah! (Otherwise, go back and specify a different model and repeat this process.)
Note: we did not get a trained model; we got a bunch of trained models, none of which we will actually use and all of which we will immediately discard. What we found was that the “specified model”, e.g. random forest, was a good choice for this problem.
Get the Performance Estimate
Armed with a specified model we like, we train this specified model on the entirety of rest_of_data. Sweet.
Now we load the holdout_data and run it through the feature engineering pipeline. We test our trained-on-rest-of-data specified model on the holdout_data. This gives us our performance estimate.
We hold a silent sort of intuition about performance at this step because rest_of_data is necessarily larger than any training set used during cross validation.
The intuition is that the specified model trained on this larger set would not have higher variation in performance and on average will perform at least as well as the average performance seen during cross validation. However, to check this we would need to repeat the steps from “First partition of Data” through this one multiple times.
NOTE: We do not assume it will perform at or better than average performance seen in cross validation. That is a very different assumption.
NOTE: we did not get a trained model; we got a trained model which we will immediately discard. What we found was a better estimate for in-production performance of the “specified model”, e.g. random forest.
Train Your Final Model
Assuming our performance estimate is sufficient, now we train the specified model on the entire_dataset. This is the trained model we use for production and/or decision making. This is our final model.
Monitoring & Maintenance
Until, as always, we iterate.
Hope this gave a little more insight to cross-validation in practice!
The Impact Hypothesis: After Thoughts
I recently wrote a piece on the impact hypothesis–that guess we make about how we turn the output of a data science project into impact. The tldr (but, you know, actually do read it) is that successful data science projects often fail to produce impact because we assume that they will. And that needs to change.
The Idea, in brief
Too often it’s taken for granted that if the algorithm is performing well then the business will improve. However, there’s almost always a step we need in order to take data science output (e.g. predicting churned customers) and create impact (e.g. fewer churned customers).
The step in between is the how we transform data science output into impact (e.g. targeting those predicted would-churn customers with promotions). It’s often assumed the how will happen. But if your assumption proves false, even amazing data science can not be impactful.
Instead of assuming the how will happen, we should explicitly state it as a hypothesis, critically scope it, and communicate it to all stakeholders.
This task should generally fall to the project manager or a nontechnical stakeholder–but its results should be shared with nontechnical and technical team members alike (that includes the data science team!).
If you incorporate this into your project scoping process, I guarantee you’ll have much more impactful projects and a much happier data science team.
So how come you’ve never hear of it?
At this point you may be wondering, if the impact hypothesis is so important why is it so often overlooked? And also, why have you never heard of it?
We conflate resource allocation with importance. The data science part of the project is the part that demands the most investment in terms of time, personell-power, and opportunity costs. Because we allocate it those resources, we also tend to give it all the attention during planning as well.
In reality, planning and scoping should be dedicated according to how critical something is to the success of a project. (Of course, don’t take longer than is need to accomplish the task. Dur.) We know that if the impact hypothesis fails, the project can not succeed. Therefore it easily merits a dedicated critique.
The impact hypothesis is implied. This is a problem for many reasons. The biggest is that implicitness removes ownership. So often the impact hypothesis goes unstated, leaving it both nebulous and anonymous.
The hypothesis needs to be made explicit so that it can be challenged, defended, and adjusted. Without a clear statement, the how goes without critique because there is nothing to be critiqued.
If someone does challenge an unstated hypothesis, it is likely to become a shapeshifter of sorts; one that morphs slightly whenever a hole is identified, as hands are waved about it, dismissing and dodging valid concerns.
Without ownership there is no one to come to when a flaw in the hypothesis is uncovered. Just the act of writing down the hypothesis will clarify what it is and where it needs to be vetted.
The hypothesis is assumed to be correct. This is in part a result of attribution issue. Having no notion of ownership often implies its ‘common knowledge.’ That is, a lack of ownership implies no one owns the idea because it’s so obvious correct. We should accept ‘obvious’ for an impact hypothesis. It’s too critical to the project.
Sometimes the hypothesis is assumed to be correct because it appears to be straightforward or trivial. Unfortunately, the appearance of simplicity often belies an idea that is no simpler to execute than those that are clumsy to describe.
Even if the hypothesis really is simple, it still needs to be challenged. This hypothesis is the only thing that connects the data science project to the business impact. It’s the only thing that justifies devoting the resources and personnel to a major project. Certainly it merits its own scoping.
It wasn’t named. The step didn’t have a name. That shortcoming is in part because we’re all still figuring out this new(ish) data science thing. This idea isn’t novel–nontechnical scoping is already a part of effective cross-team collaboration. Naming it is just a way to acknowledge that nontechnical scoping it is also critical in data science projects.
Now go forth and hypothesize!
Talk the Talk: Data Science Jargon for Everyone Else (Part 1: The Basics)
Bite-sized bits of data science for the non-data scientist
Disclaimer: All * terms to be defined at a later point. As well as many others
data scientist: a role that includes basic engineering, analytics, and statistics; often builds machine learning models
- depending on the company, might be a product analyst, research scientists, statistician, AI specialist, or other
- a job title made up by a guy at Facebook and a guy at LinkedIn trying to get better candidates for advanced analytics positions
in a sentence: We need to hire a data scientist!
data science: advanced analytics, plus coding and machine learning
- producing insights for decision makers or putting models into production*
- 80% cleaning data, 20% data sciencing
in a sentence: We need to hire a data science team!
artificial intelligence: the ability for a machine to produce inference from input without human directive
- used to describe everything from basic data science to self driving cars to Ava’s Ex Machina
- no one aggress a definition
- “AI is whatever hasn’t been done yet.” ~ Douglas Hofstadter
in a sentence: We just got our AI startup funded–join our team and become our first data scientist!
machine learning: algorithms and statistical models that enable computers to uncover patterns in data
- claims a large part of old school statistics as its own, plus some fun new algorithms
- it’s probably logistic regression. or a random forest….or linear regression.
- AI if you’re feeling fancy
in a sentence: We need you to machine learn [the core of our startup].
model: a hypothesized relationship about the data, usually associated with an algorithm
- may be used to refer to the algorithm itself, the relationship, a fit* model, the statistical model, maybe the mathematical model, perhaps Emily Ratajkowski, certainly not a small locomotive
- it’s probably logistic regression. or random forest….or linear regression.
in a sentence: I’m training a model. (and not how to turn left)
feature: an input to the model; x value; a predictor; a column of input data
- when a data scientist is ‘engineering,’ this is usually what they’re making
- if your model says that wine points predicts price, then sommeliers’ ratings is your feature
in a sentence: Feature engineering will make or break this model.
label: the output of a predictive model; y value; the column of output data
- the thing the startup got funded to predict
Talk the Talk: Data Science Jargon for Everyone Else (Prologue)
“Data scientist is the sexiest job that has ever or will ever exist.”
These are just some of the things we hear about data, AI, and data science everyday. By now most of us can parrot back the sentiments in loose, noncommittal terms. Some can even weave the tropes, aphorisms, and hype into sentences. Usually that’s more than enough to convince leadership to hire a data scientist or to flesh out a slide as to why those hires were so pivotal.
But beyond the pitch and the powerpoint, we can’t rely on vague-ities. Not if we want to make the most out of those hires. If we want to capitalize on what data science can offer, we need to communicate in specifics, particulars, and with common understanding.
That is what this series is for; to empower you to communicate effectively with your data science, AI, and data teams.
This series is not going to make you a data scientist–and that’s not the intention. You don’t need to know how to train a model to know what it means to do so. You don’t need to be able to engineer features to know what data scientists are doing when they say that. You don’t need to know what cross-validation is to know why it’s important. You don’t need to know the details to understand the idea.
If you believe you can communicate without sharing a common language, I encourage you to discuss your favorite hobby with someone uninitiated in it. See how long you can go without explaining a term.
The fact is, jargon is everywhere–and it’s particularly prominent in this field. So, yes, we “better get used to it.” But jargon exists for a reason: it enables us to communicate specific, complex ideas quickly. And this field is chock-full of specific, complex ideas. Jargon just makes those ideas easier to communicate. So, really, we ought to embrace it.
Now, data scientists have this easy; they learn the jargon while they learn the job. It’s second nature for them to use the right words to describe their work. It’s clumsy, imprecise, and generally inaccurate to translate the right words into those that outsiders will accept.
So, let’s let the data scientists use the right words.
But how can you do that? By learning those words.
For all you not-data scientists out there, I’m making a cheat sheet.
If you want to learn the jargon, instead of just reading why it’s important to learn it, look for “Talk the Talk” posts or search the “jargon” tag. That’s where you’ll find bite-size installments of a growing cheat sheet of data science terms for non-data scientist.
When Stack Exchange Fails
….or How to Answer Your Own Questions
This walk-thru shows how to hunt down the answer to an implementation question. The example references sklearn, github, and python. The post is intended for data scientists new to coding and anyone looking for a guide to answering their own code questions.
Does sklearn’s
gridsearchCVuse the same cross validation train/test splits for evaluating each hyperparameter combination?
A student recently asked me the above question. Well, he didn’t pose it as formally as all that, but this was the underlying idea. I had to think for a minute. I knew what I assumed the implementation was, but I didn’t know for sure. When I told him I didn’t know but I could find out he indicated that his question was more of a moment’s curiosity than any real interest. I could’ve left it there. But now I was curious. And so began this blog post.
I began my research as any good data scientist does:
It’s true, this question is a little bit nit-picky. So, I wasn’t completely surprised when the answer didn’t bubble right up to the top of my google results.
I had to break out my real gumshoe skills: I added “stackexchange” to my query.
Now I had googled my question–twice–and no useful results. What was a data scientist to do?
Before losing all hope, I rephrased the question a few times (always good practice, but particularly useful in data science with its many terms for the same thing). Yet still no luck. The internet’s forums held no answers for me. This only made me more determined to find the answer.
What now?
There’s always the option to….read the documentation (which I did). But, as often is the case with questions that are not already easily google-able, the documentation did not answer the question I was asking.
“Fine.” I thought. “I’ll answer the question myself.”
How do you answer a question about implementation?
Look at the implementation. I.e, read the code.
Now, this is where many newer data scientists feel a bit uneasy. And that’s why I’m taking you on this adventure with me.
The Wonderland of Someone Else’s Code
Read the sklearn code?!?
If it feels like an invasion, it’s not. If it feels scary, it won’t be (after a you get used to it.) But if it sounds…dangerous? That’s because it is.
…Insofar as a rabbit hole is dangerous. Much like Alice’s journey through Wonderland, digging through someone else’s code can be an adventure fraught with enticing diversions, distracting enticements, and an entirely mad import party. It’s easy to find yourself in the Wonderland of someone else’s repo hours after you started, no closer to an answer, and having mostly forgotten which rabbit you followed here in the first place.
Much like Alice’s adventure, it’s a personal journey too. Reading someone else’s code can reveal a lot about you as a coder and as a colleague. But, that’s for another blog post .
Warned of the dangers, with our wits about us, and with our question firmly in hand (seriously–it helps to right it down), we begin our journey.
How do we find this rabbit hole of code in the first place? A simple google search of “GridSearchCV sklearn github” will get us fairly close.
Clicking through the first result get us to the .py file we need.
We know that GridSearchCV is a class, so we’re looking for the class definition. CMD(CTRL) + F “class GridSearchCV” will take us here.

We note that GridSearchCV inherits from BaseSearchCV. Right now, this could be a costly diversion. But, there’s a good chance we might need this later. So this is good a breadcrumb to mentally pickup.
And–Great! A docstring!
Oh, wait–a 300 line docstring. If we have the time we could peruse it, but if we skim it we notice it’s very similar to the documentation (which makes sense). We don’t expect to find any new information there, so we make the judgment call and pass by this diversion.
We scroll to the end of that lengthy docstring and find there are only two methods defined for this class (__init__ and _run_search). _run_search is the one we need.

Ok. So what’s this evaluate_candidates?
We can follow the same method of operation and search for def evaluate_candidates. With a little (ok, a lot) of scrolling we’ll see it’s a method of the BaseSearchCV class. Now, is when we pause to pat ourselves on the back for noting the inheritance earlier (pat, pat, pat).
Here we can finally start to inspect the implementation:

So….that’s a lot. After a cursory reading through the code, it becomes clear that the real work we’re concerned with happens here:

product, if you’re not familiar, is imported from the the fabulous itertools module which provides combinatorial functions like combinations, permutations, and product (used here).
(Worthy Read for Later: itertools
There’s one product call for the candidate_params and cv.split. What does product yield? It returns an iterator whose elements comprise the cartesian product of the arguments passed to it.
Now we’ve got distractions at every corner. We could chase cv, itertools, parallel,BaseSearchCV, or any of the other fun things.
This is where having our wits about us helps. We can look back to our scribbled question: “Does sklearn’s gridsearchCV use the same cross validation test splits for evaluating each hyperparameter combination?” Despite the tempting distractions, we are getting very close to the answer. Let’s focus on that product call.
Ok, great. So we have the cartesian product of candidate_params and cv.split(X, y, groups).
Thank Guido for readability counting, am I right?
From here it’s a safe bet that candidate_params are indeed the candidate parameters for our grid search. cv is cross validation and split returns precisely what we’d expect.
It might look concerning that one of the arguments passed to product is itself a call to the split method of cv. You might wonder “Is it called multiple times? Will it generate new cv splits for every element?”
Fear not, for product and split behave just as we would hope.
split returns a generator, a discussion of which merits its own post. For these purposes it’s enough to say split acts like an iterator (e.g. list).

… and product treats it the same as it would a list.
Let’s say we didn’t already know that (because we probably didn’t). When it comes to many common functions, we can often quickly test behavior with toy cases to answer our questions:
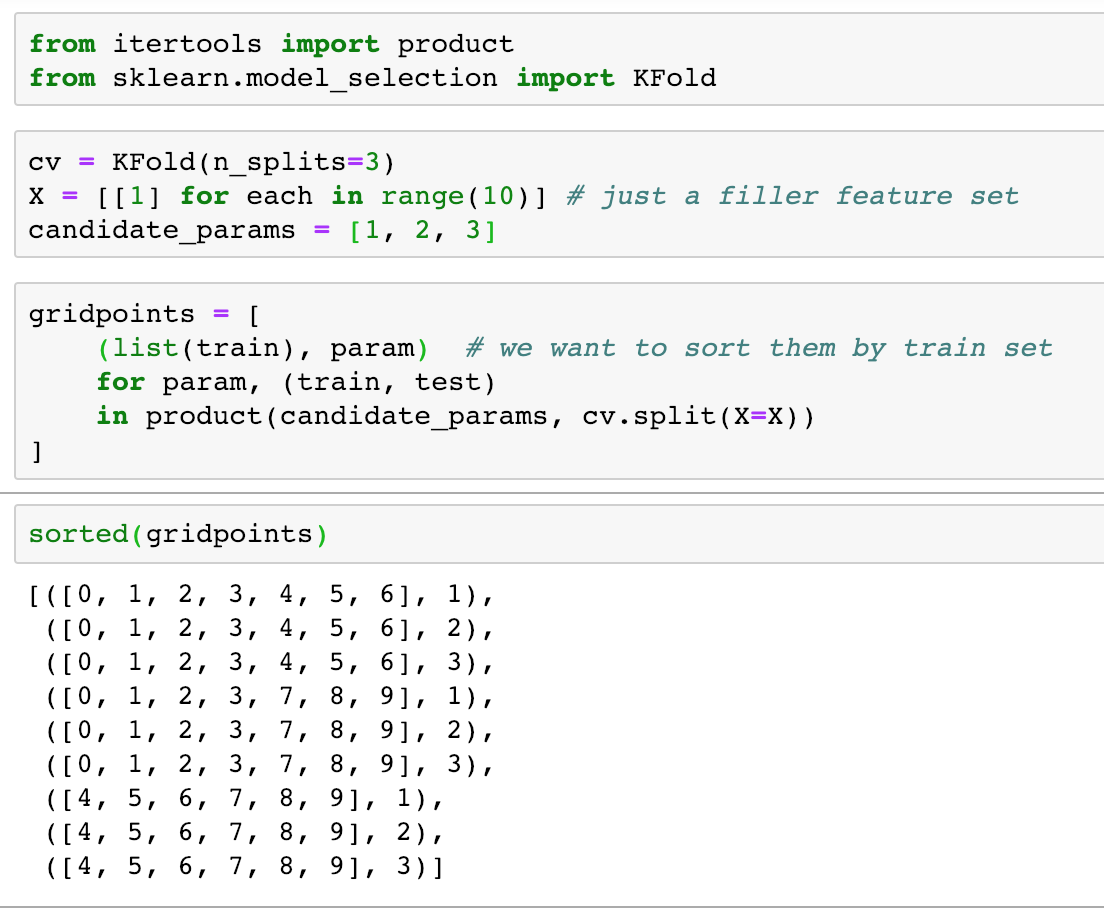
Great! Now all we have to do is look at this in its larger context:

It looks like delayed and parallel will help us manage this execution. We could go hunt down how they do this, and it might be a worthy journey when time is not of the essence. For right now, we’ve got our wits about us and we’ve already answered our question:
sklearn’s gridsearchCV uses the same cross validation train/test splits for evaluating each hyperparameter combination.
There we have it. We’ve answered out question (yes!), we’ve might’ve learned about a cool new module (itertools), we even bookmarked a few diversions for if-we-ever-have-extra-time (parallel, generators, BaseSearchCV,….), and we did it all without too much distraction. Maybe we can even take lunch today!
Special thanks to Damien Martin, a fellow Metis SDS, for giving my post a good once-over. You can find his blog at kiwidamien.github.io where you might want to start by reading his empirical Bayes series.
